
If you’ve followed our progress at Embark, you have seen us teasing work we’ve been doing to automate game animation using machine learning. I’m Tom, and I’m part of Embark’s machine learning team, here to describe this effort in a bit more detail.
So who are we, you may ask? At Embark, we’ve taken a hard look at how we go about creating game content, and as part of that, we have come to embrace machine learning and procedural content across many of our workflows. I’m part of a group of a dozen engineers, researchers, tech artists, designers, and animators involved in this endeavor.
https://community.today.com/user/123movies-watch-the-croods-a-new-age-2020-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-the-little-things-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-judas-and-the-black-messiah-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-monster-hunter-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-the-marksman-2021-full-movie-online-free-hd
Our larger goal is to apply the latest research from around the world to create fun and interesting gameplay experiences, that can then be used by our game teams. That’s also what makes this team special, the fact that our work is practical, rather than just research-oriented.
Animation is a big bottleneck in all game development. Characters or creatures have to be designed and scripted manually, to achieve seemingly realistic interactions with the world. That makes it hard to achieve scale without growing your game team.
https://community.today.com/user/123movies-watch-palmer-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-nomadland-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-raya-and-the-last-dragon-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-the-world-to-come-2021-full-movie-online-free-hd
https://community.today.com/user/123movies-watch-demon-slayer-the-movie-mugen-train-2020-online-full-movie-free-hd
So over the past two years, we’ve continued down the path of physical animation based on reinforcement learning. In short, that means we train physically-based machines to walk by giving them rewards for doing the right things — like virtual dog treats.
As you’ll see in the examples below, achieving good movement behaviors can lead to more immersive and interesting gameplay, where the world becomes truly alive — where there aren’t any pre-made animations, stuttering transitions between poses, or weird ragdolls.
Instead our agent — you can think of it as the AI player — observes its body and the world around it; and decides how to move the legs over the next few frames. This means that if the agent collides, is hit by, or generates some force by itself; it can adapt immediately for each unique situation. If you trip on a rock or get hit by a snowball you’ll do something unique every time — because no snowball or rock is the same.
https://community.today.com/user/123movies-watch-demon-slayer-the-movie-mugen-train-2020-full-movie-online-free-hd
https://community.today.com/user/123movies-watch-willys-wonderland-2021-full-movie-online-free-hd
https://community.today.com/user/123movies-watch-tom-and-jerry-2021-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-godzilla-vs-kong-2021-full-movie-online-free-hd
https://community.today.com/user/123movies-watch-malcolm-marie-2021-full-movie-online-free-hd
Machine-taught AI-agents get rewards for doing the right things — like virtual dog treats.
Below; you can see one of our robots get hit by an object. Notice that it reacts and attempts to balance and recover after impact while moving forward towards its goal.
And in this next example, you can see that our agent has learned to traverse complex environments, climbing difficult and uneven terrain with relative ease.
https://community.today.com/user/123movies-watch-avengers-endgame-2019-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-the-king-of-staten-island-2020-full-movie-online-free-hd
https://community.today.com/user/123movies-watch-greenland-2020-full-movie-online-free-hd
https://community.today.com/user/123movies-watch-spider-man-far-from-home-2019-online-full-movie-free-hd
https://community.today.com/user/123movies-watch-the-invisible-man-2020-online-full-movie-free-hd
https://steemkr.com/lifes/@zenairama/transforming-animation-with-machine-learning
https://cox.tribe.so/post/https-community-today-com-user-123movies-watch-the-croods-a-new-age-2020-on--603a69573e2f1b6c1b75c82f
https://paiza.io/projects/2uVhwCljVVXiA9v4Na1-Xg?language=php
https://onlinegdb.com/rkgptJ_G_
https://jsfiddle.net/danilaveria/awegbspo/
https://dumpz.org/aH9R6embr7c8
http://paste.jp/9f90874c/
https://rentry.co/qmzcw
https://www.guest-articles.com/news/transforming-animation-with-machine-27-02-2021
https://www.guest-articles.com/news/with-machine-learning-transforming-animation-27-02-2021
https://www.guest-articles.com/others/transforming-animation-with-machine-learning-27-02-2021
https://www.guest-articles.com/news/transforming-animation-27-02-2021
However, achieving this gameplay isn’t the only challenge. We’re working together with a very talented set of animators and game designers, and they have opinions. They want fine-grained control over the game, and machine learning will at best let them give strong recommendations.
Teaching others how to best use machine learning and what you can and can’t use it for is an ongoing effort. We’re getting there after a year of working together, but introducing new procedural tools requires acceptance and a change of mindset, regardless if you’re familiar with the technology or not.
In this new procedural world, we’re changing the role of both our animators and designers. While still crucial to the team, the role of our animators is no longer to draw animation curves, creating state transitions, or blending clips. They’re here to train agents, just like us. While engineers like myself approach it from an algorithmic perspective, they do it with an animator’s eye for detail: Does it look nice? Does it telegraph correctly? Does it look credible? Much like a choreographer, they direct the feeling and intent of the final movement, rather than moving each leg themselves.
Introducing new procedural tools requires acceptance and a change of mindset
In this new workflow, our colleagues have to work at a higher level of abstraction: instead of deciding animation curves, they describe movement behaviors that the machine learning should respect. Similarly, our game designers aren’t able to decide exact movements for an agent. Instead, they provide goals and instructions that are then fulfilled by the agent based on how it was trained.
The monkey wrench in all of this is that we’re working—obviously — in a game engine. The research we base our work on uses completely different setups; focused on scientifically accurate high-resolution physics. We, on the other hand, need to take performance into consideration, and have to make this work in an engine that’s designed to trade physics correctness for higher frame rates.
So not only are we building our own machine learning platform, infrastructure, and plugin for Unreal Engine. We’re also building layers around the physics engine to improve and control its simulation capabilities, to get the results we want.
Even with tuning the physics, the nature of machine learning means the results can be unpredictable. Just like with Deep Thought in The Hitchhiker’s Guide to the Galaxy, asking the wrong question leads to confusing and unexpected behaviors.
Getting where we are today has meant lots of work, effort, failing, and starting over.
But it’s been worth the while. We’ve arrived at a workflow that allows us to create much more content with a comparatively small team, as we’re not dependent on an army of animators to script every single movement and encounter that we put in the game. In fact, our aim is that our designers should be able to teach agents without input from engineers or animators at all.
And seeing a self-taught, physics-based creature move and react to its surroundings, attempt to balance itself, and try to continue to move even when you throw stuff at it or take away a limb — just like you would expect it to — is really something. It gives rise to emergent gameplay — moments in games that even we as creators of the game could never have anticipated.
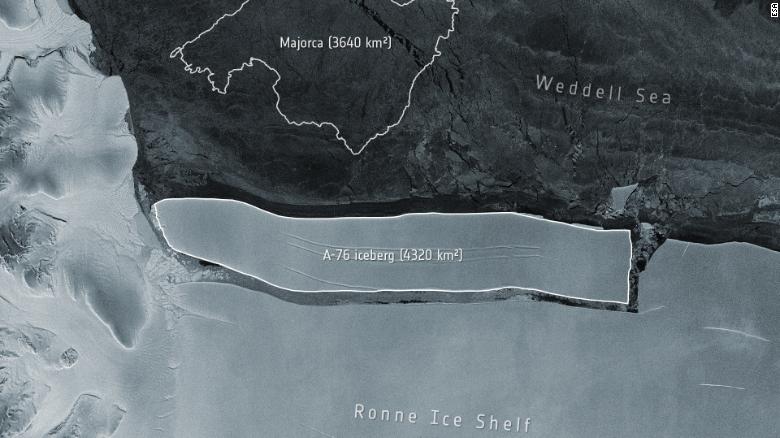
- Worlds largest iceberg breaks off from Antarctica a giant floating piece of ice close to 80 times the size of Manhattan

- Medical cannabis uses the cannabis plant or the chemicals in it to treat diseases or ailments. Medical cannabis received a lot of attention.

- also no less than 5 pictures., that may contain systems Oracle Database Oracle 1Z0-083 Oracle Database Administration II Exam into Oracle your curriculum.

- Republican legislators in other states have also been drafting proposals to ban or limit them. A bill introduced in the Arkansas Legislature on